본 강좌에서는 Object Detection의 개념과 이를 위한 YOLO알고리즘의 기초에 대하여 정리한다.
하기 블로그에 더 잘 정리되어 있다..(누군지 존경스럽다.)
Object Localization
-
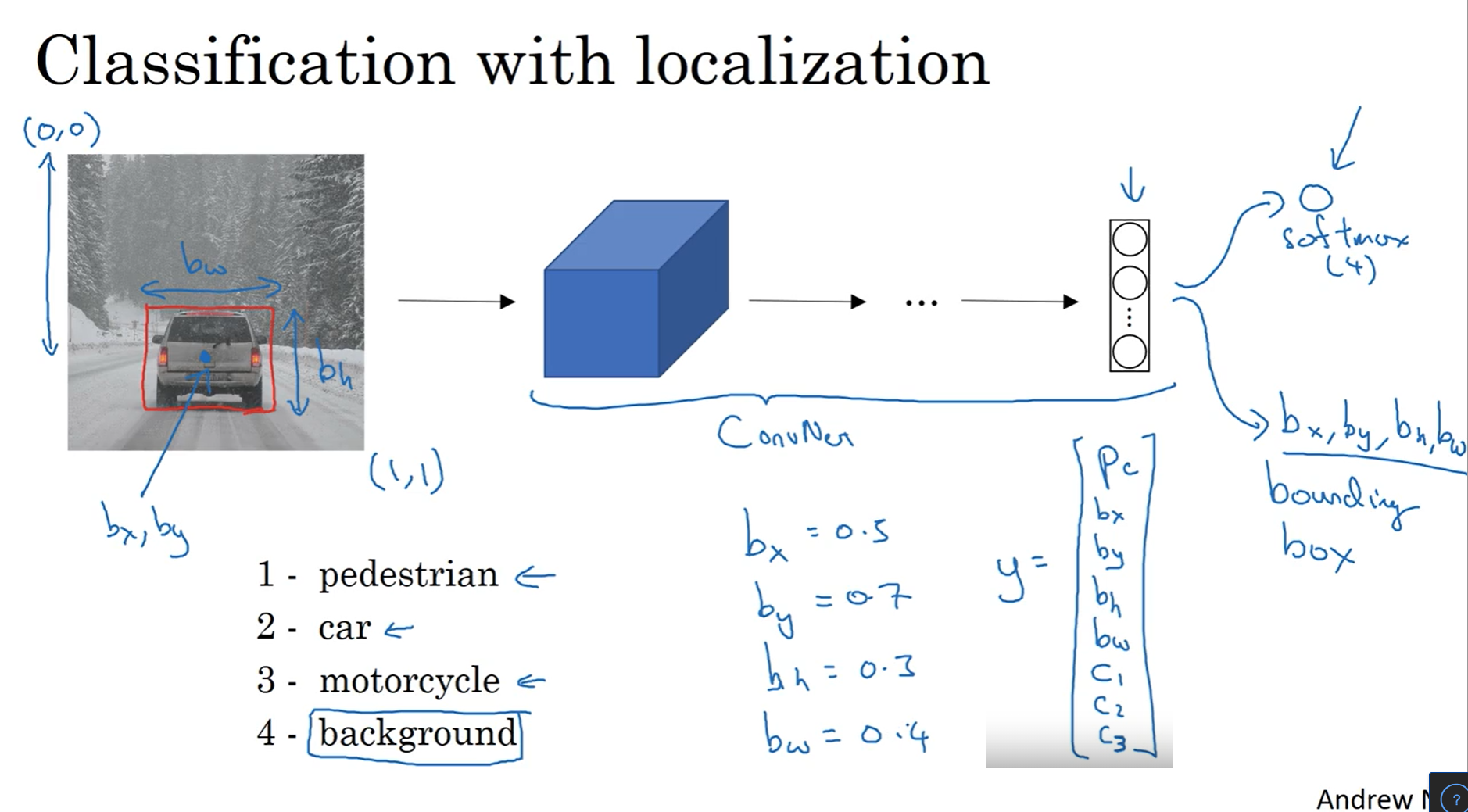
Classification with localization : object class 뿐 아니라, 알고리즘이 object를 대상으로 bounding box를 표시하는 것을 의미
-
이를 위해 이미지를 CNN에 입력 출력으로 class 뿐만 아니라 이미지에 object가 존재할 확률($p_c$), Bounding box의 위치 및 크기를 같이 출력(Bx, By, Bh, Bw)
-
Loss function은 MSE(mean squared error)를 사용한다면 Y 각 요소의 에러의 합과 같다. Pc가 0일 경우 Pc의 에러만 사용한다. $$ L(\hat{y},y) = \begin{cases} (\hat{y}_1-y_1)^2+(\hat{y}_2-y_2)^2+\cdots+(\hat{y}_8-y_8)^2 & \text{if } y_1=1 \\ (\hat{y}_1-y_1)^2 & \text{if } y_1=0 \end{cases} $$
-
MSE를 예시로 설명했지만, $c_1$, $c_2$, $c_3$에는 log-likelihood loss와 softmax를 사용하고, bounding box 정보에는 MSE를, 그리고 $p_c$ 에는 Logistic Regression Loss를 사용할 수도 있다.
Landmark Detection
- Bounding box가 아닌 일반적인 Face recognition이나 pose detection의 같은 일반적인 경우 이미지의 주요 포인트(landmark)를 X와 Y의 좌표로 나타낼 수 있다.
Object Detection
- Sliding Windows Detection 알고리즘을 사용해서 Object Detection을 위해 ConvNet을 사용하는 방법 알아본다. (CS231n 강의에서는 Sliding window는 하지말라던데 아마 이해를 위해 넣어놓은 것 같다.)
- 방법은 하기와 같다.
- object의 클래스를 구분할 수 있는 모델 생성
- 전체 이미지 중 특정 size의 window를 골라 탐색
- window 살짝 옮겨서 반복
- 더 큰 박스를 이용하여 반복

- 그러나 이 방법은 computing cost가 높다. 다음 절에서 이를 줄일 수 있는 방법을 알아본다
Convolutional Implementation of Sliding Windows
- Sliding window 방법은 매우 느린데 이를 해결하기 위해 FC(Full connected) layer를 Convolutional Layer로 튜닝하는 것을 알아보자. 절차는 하기와 같다
- FC layer를 이와 같은 output을 낼 수 있는 Filter로 변환
- sliding window 시 각각 수행이 아닌 convolution처럼 한번에 연산. 이렇게 하면 중복되는 연산은 공유가 가능하다.
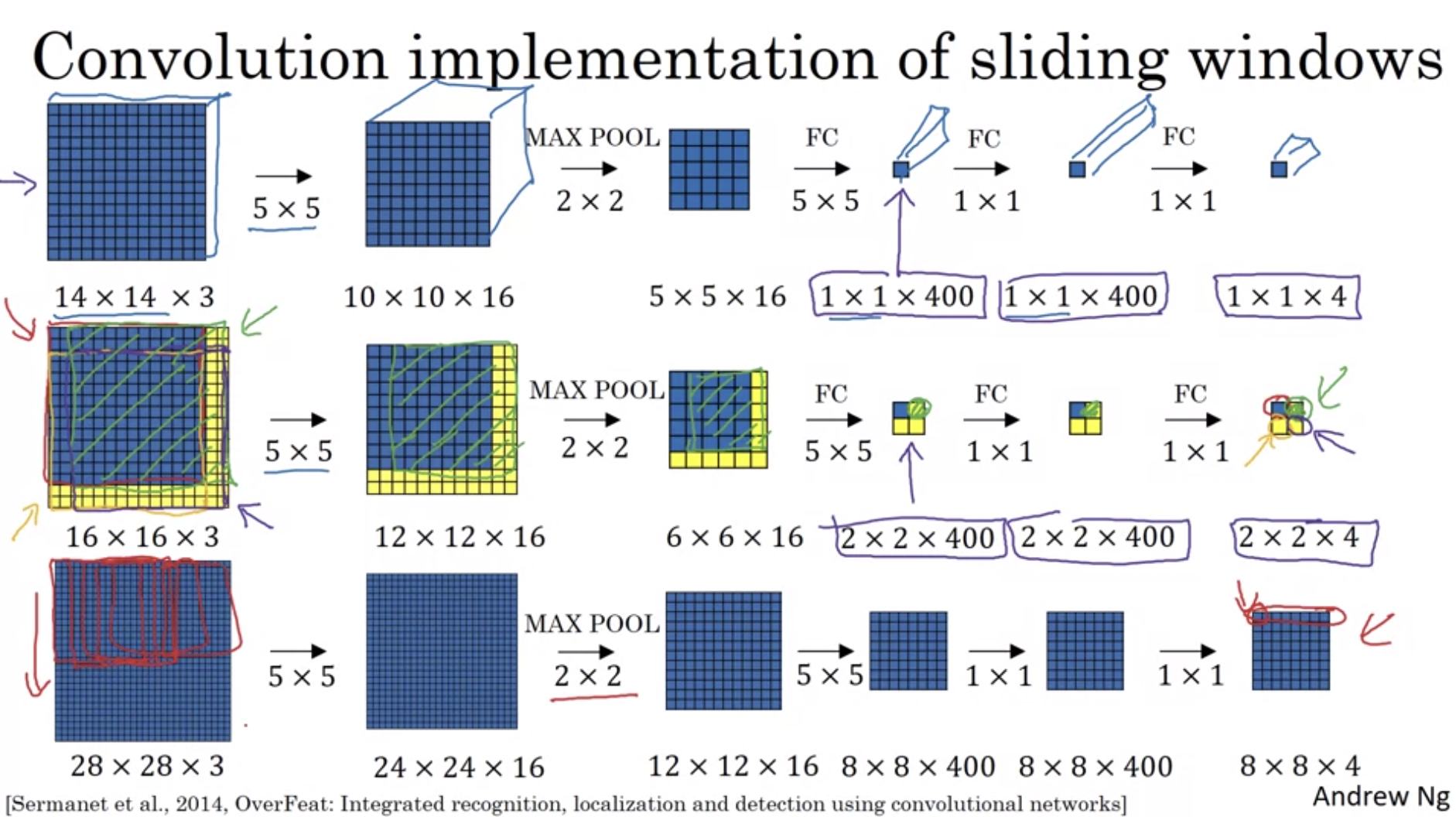
- 그러나 이 방법은 bounding box의 위치가 정확하지 않다는 단점이 있는데 이를 아래 방법으르 해결한다.
Bounding Box Predictions
- Sliding window 방법은 object가 그 위치에 있지 않거나 일부분만 걸칠 수 있는데 이를 YOLO 알고리즘으로 극복 가능하다.
- 전체 이미지에 3x3 grid 를 설정(보통은 19x19 사용)
- 위에서 배운 object localization을 각각의 grid에 적용, 즉 이해한바로는 test set에서 각각의 그리드에 localization방법으로 labeling하고 학습
- 각 grid에 object가 존재한다면 object의 중간점을 위해서 object를 할당한다. 이때 object의 크기는 1이 넘어갈 수 있다.(gird를 넘어가거나 클 수 있으므로)
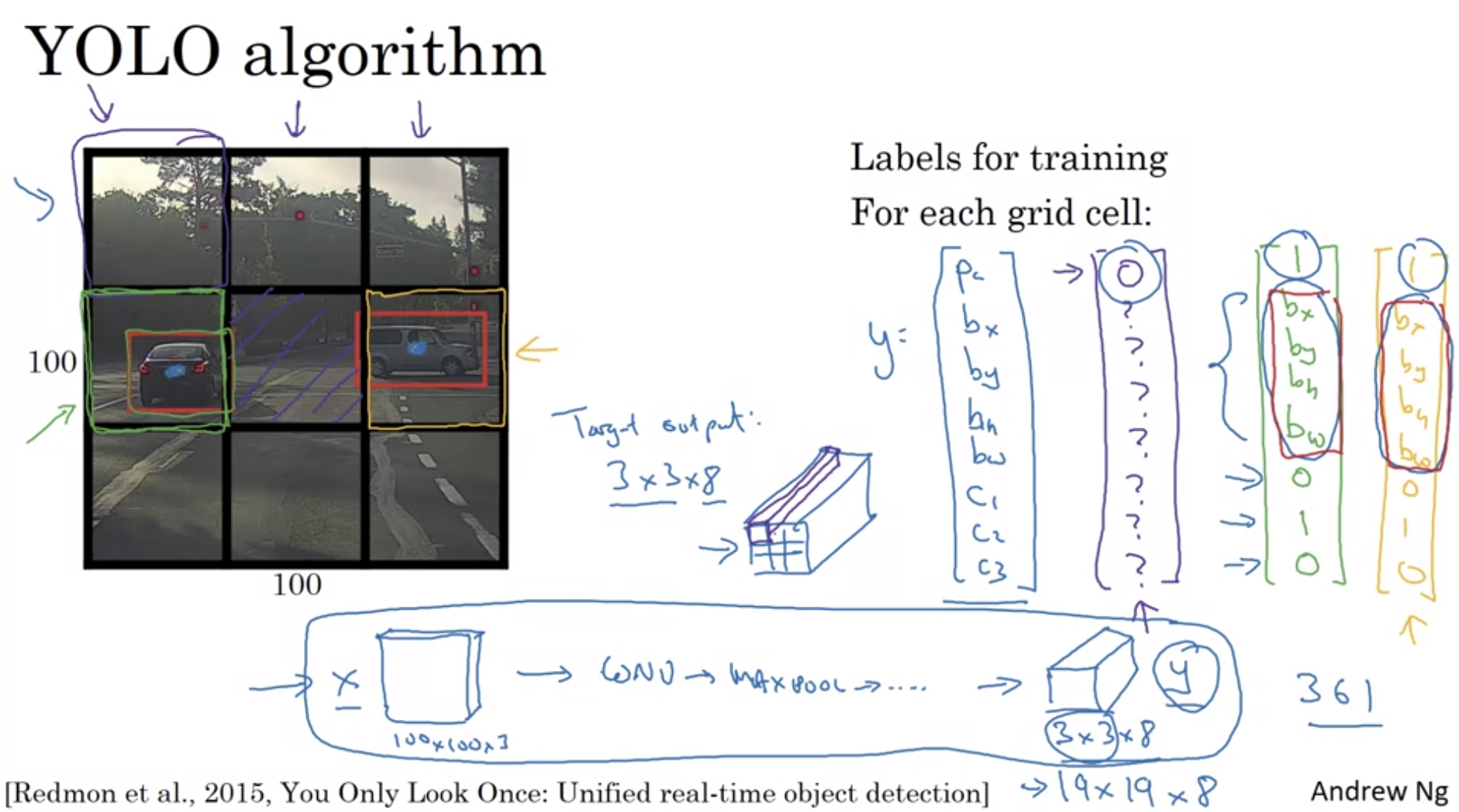
- Bounding box를 설정하는 방법은 여러가지가 있지만(ex. PCA 이용), YOLO논문을 살펴보면 잘 동작할 수 있도록 파라미터화 된 것들이 있다.
Intersection Over Union
- Intersection over union(IoU)은 Object Detection이 잘 동작하는지 판단하기 위한 함수
- labeling 된 bounding box와 예측한 bounding box의 전체 넓이와 겹치는 부분 넓이의 비율을 계산
- 보통 0.5 이상이면 예측한 bounding box의 결과가 옳다고 판단
Non-max Suppression
- 현재까지 알아본 Object detection의 문제점은 한 Object를 여러번 탐지할 수 있다는 것이다. 즉 한 object가 한 그리드 이상에의 면적을 차지할 경우 이 object의 중심점이 여러 Cell에서 탐지 될 수 있다.
- 이 경우에 Non-max suppression을 사용하면 알고리즘이 하나의 object를 하나의 cell에서 한번만 탐지할 수 있다.
- 만약 분류 class 가 1개여서 $p_c$가 class의 확률이라 가정한다. (실제로는 클래스는 여러개)
- $p_c$를 조사하여 가장 큰 것만 취함
- 나머지 box와 $p_c$값이 가장 큰 박스와 IoU 조사
- IoU가 높은 박스는 제거
- 만약 class가 여러개라면 class 당 non-max suppression을 수행한다.

Anchor Boxes
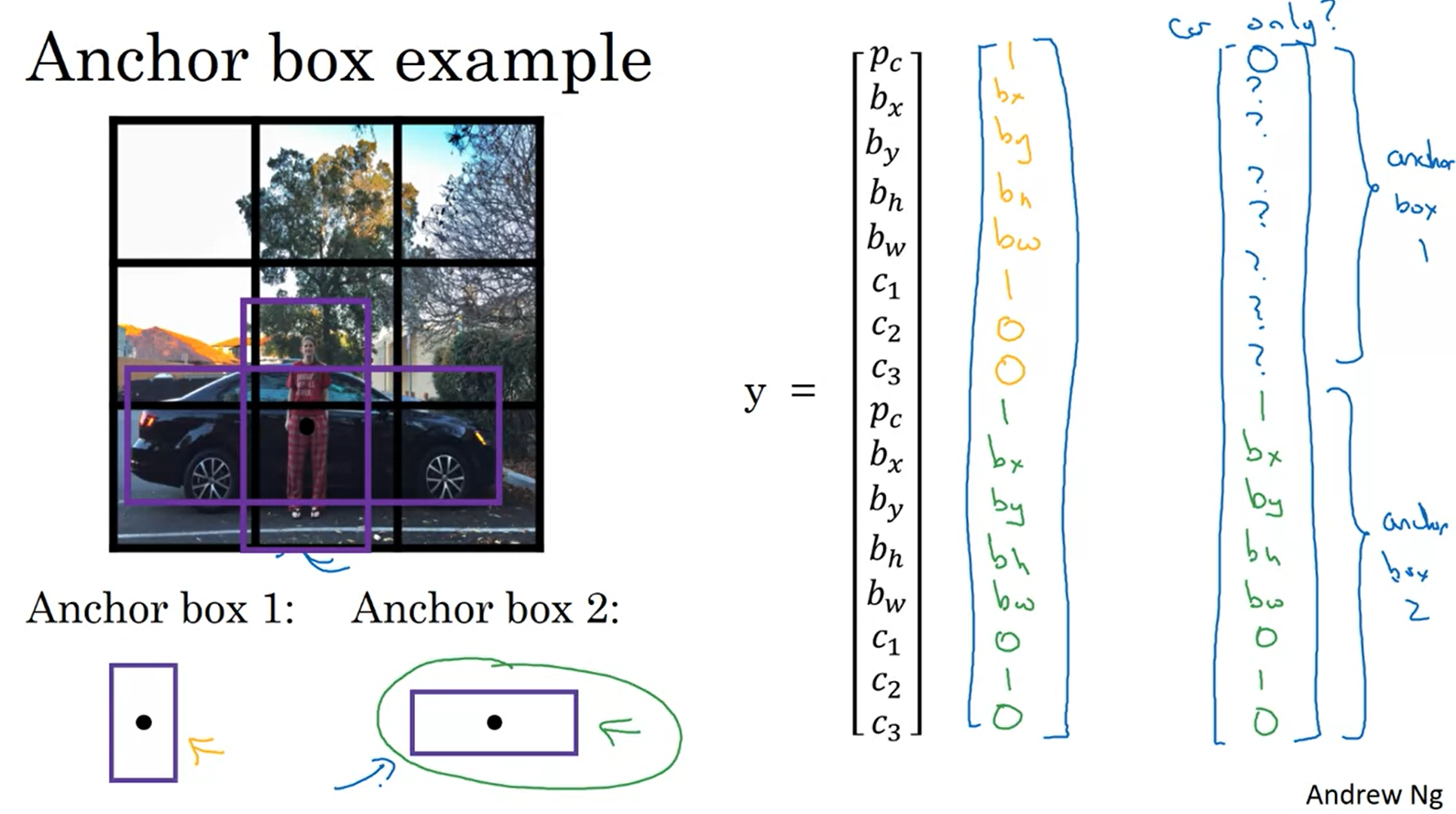
- 현재까지 소개한 알고리즘의 문제점 중 하나는 각 grid cell이 오직 하나의 object만 감지할 수 있다는 것이며 이를 anchor box라는 아이디어를 가지고 해결할 수 있다.
- anchor 박스의 모양을 미리 정의
- 각각의 anchor box는 각 output을 가지게 한다.
- anchor box의 선택은 manual로 선택을 할 수도 있고, K-mean알고리즘을 통해서 얻고자하는 유형의 object모양 끼리 그룹화 할 수도 있다.
YOLO Algorithm
- 위의 내용을 모두 종합하여 YOLO object detection algorithm을 정리해보자
- 이미지의 anchor box와 grid 수를 정하고 이와 같이 labeling된 데이터 셋으로 모델을 학습
- 상기 모델로 추론을 수행하게 되면 각 grid cell은 anchor box 수만큼의 bounding box를 가질 수 있다. 여기서 낮은 확률을 가지는 예측결과는 제거하고 각 class에 non-max suppression을 적용하여 최종 예측 결과를 얻는다.
- YOLO 알고리즘은 가장 효과적인 Object Detection 알고리즘 중 하나