Graph Abstraction for ML Models
Graph abstraction은 데이터 flow와 구조를 나타내기 위한 Machine Learning 컴파일러의 주요 기술이다. 모델을 Graph representaion으로 추상화 함으로써 컴파일러는 다양한 최적화나 성능 향상을 수행할 수 있다.
What is Graph Abstraction?
Graph abstraction은 ML model을 Graph로 나타내기 위한 프로세스이며 컴파일러가 모델의 파트 사이의 dependency와 relation을 분석하게 해준다.
- node : computational operations (e.g., matrix multiplication, convolution)
- edge : Operation 간 data의 흐름을 나타냄
Key Features of Relax
- First-class symbolic shape : Relax 는 Tensor의 차원을 표현할 때 Symblic shape를 사용. tensor operators와 function calls 간의 dynamic shape relationship을 전역 추적할 수 있게 함
- (역자주) First-class는 프로그래밍에서 해당 요소가 함수의 인자 리턴 값으로 자유롭게 사용될 수 있고 컴파일러가 최적화에 활용될 수 있음을 의미, 즉 relax는 동적입력을 지원하고 이것이 컴파일러 단에서 최적화가 가능하며 전체 모델에서 Shape 분석이 가능함을 의미한다. TIR도 Dynamic Shape를 지원하지만 이는 함수에서 단순한 변수 추적일뿐 shape 추론은 수동으로 해야한다. 즉 shape관계추적, 전역 최적화는 어렵다. 즉 Relax는 이 텐서의 크기를 나중에 정할 수 있으며 심볼로 최적화가 가능)
- Multi-level abstractions : Relax는 high-level neural network layer부터 low-level tensor operation까지 포함하는 cross-level abstraction을 지원
- (역자주) [Relax] 신경망 레이어 단위(Dense, ReLU, Conv2D) -> [Relax Dataflow] 텐서 연산 단위 (matmul, add, relu) -> [TIR]루프/인덱싱 기반 연산 의 변환이 하나의 통합된 시스템 안에서 자유롭게 오갈 수 있음)
- Composable transformations : relax는 모델 컴포넌트에 선택적으로 적용가능한 transformation을 제공, partial lowering / partial specialization 같은 유연한 최적화 옵션을 포함
- (역자주) 한 번에 전체 모델을 “한 가지 방식"으로 변환하거나, 특정 최적화를 적용하면 다른 최적화와 충돌하는 경우가 많으나 relax는 모델 전체가 아닌, 특정 함수/연산에만 적용 가능하다. 즉 모델을 하드웨어/용도에 맞춰 유연하게 최적화하고 커스터마이징 가능)
Understand Relax Abstraction
Relax는 ML모델에 대해 end-to-end optimize를 돕기 위한 graph abstraction. Relax는 ML모델의 structure와 data flow를 묘사한다.(모델 파트간의 dependency와 relationship 및 HW에서 실행되는 방법)
End to End Model Execution
이제부터 linear->relu->linear 모델을 활용하여 Relax를 설명한다.
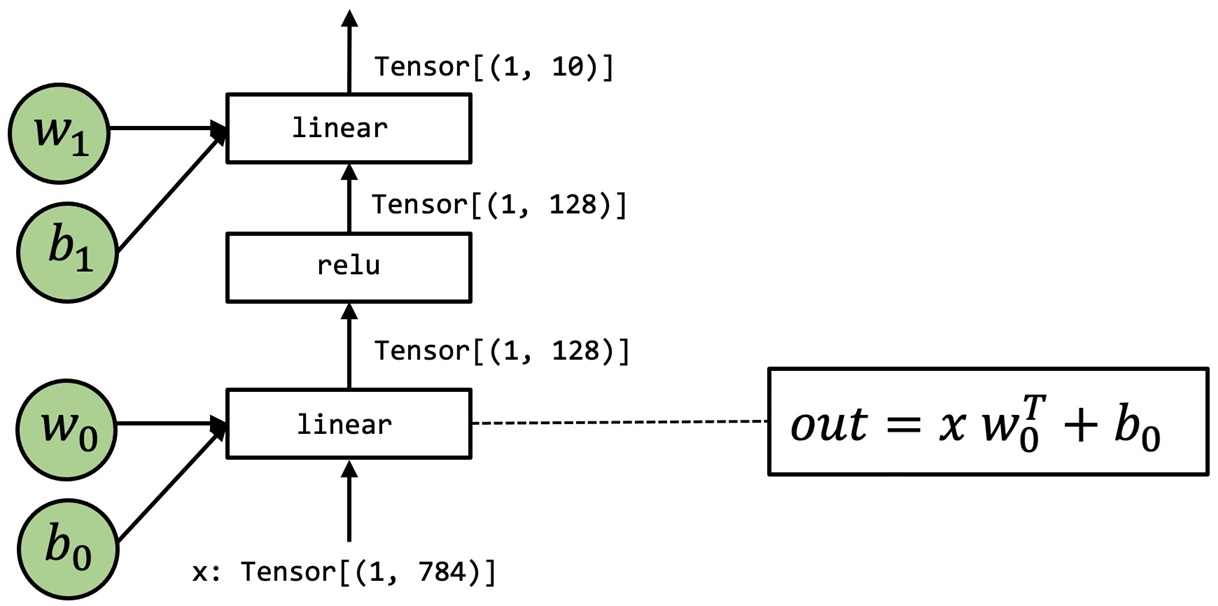
High-Level Operations Representation
위 모델을 Numpy와 Relax 모델로 하기와 같이 표현할 수 있다.
|
|
Low-Level Integration
머신러닝 컴파일러의 관점에서 array computation의 세부 사항을 살펴보기 위해 Numpy 코드를 low-level로 풀어보자(배열 함수 대신 루프 사용, numpy.empty를 통해 배열을 명시적으로 할당)
|
|
위의 코드를 활용해 Relax로 표현할 수 있다(TVMScript 구현)
|
|
위으 코드는 primitive tensor functions (T.prim_func) 과 R.function (relax function)을 포함(Relax 함수는 high-level neural network execution를 나타내기 위한 새로운 타입)
Relax Module이 symbolic shape를 지원하는 것이 중요 (main 함수의 n, linear 함수의 M,N,K), 이것은 tensor operators와 function calls 간의 dynamic shape 추적을 위한 key feature임
numpy 코드와 TVMScript를 1:1로 비교해보면 세부적인 사항을 알 수 있다.
Key Elements of Relax
Structure Info
Structure info는 relax expression의 type을 표현하기 위한 새로운 컨셉 ( TensorStructInfo, TupleStructInfo 등)
- 위의 예제어서는 inputs, outputs, 중간 결과의 shape와 dtype을 표현하기 위해 TensorStructInfo (R.Tensor)를 사용
R.call_tir
R.call_tir 함수는 primitive tensor 함수 호출을 위한 새로운 추상화, cross-level abstraction을 위한 key feature.
|
|
위의 relax코드와 이에 대응하는 numpy 코드를 비교해보자. call_tir은 destination passing을 사용한다.
- input / output은 low-level primitive function 외부에 명시적으로 할당(저수준 라이브러리 설계에서 일반적으로 사용되는 방법으로 고수준 프레임워크가 메모리 할당 결정을 처리할 수 있음)
- 모든 텐서 연산을 이 스타일로 표현할 수 있는 것은 아니나 (예를 들어 입력에 따라 출력 형태가 달라지는 연산) 일반적으로 가능하면 저수준 함수를 이 스타일로 작성하는 것이 일반적
Dataflow Block
relax function의 중요한 다른 element는 R.dataflow()
|
|
Relax의 dataflow를 설명하기 전 pure와 side-effect의 개념에 대해 알아야 한다
- pure 함수 : 입력만을 읽고, 출력을 만들어내는 함수 (입력 및 외부 메모리 영역을 변경하지 않음)
- Side-effect : 함수가 단순히 결과를 반환하는 것 외에, 프로그램의 다른 부분(메모리, 전역 변수 등)에 영향을 미치는 것
- 즉 pure(side-effect free) 하다는 것은 입력을 읽어 출력을 내보낼때 입력이나 다른 외부 메모리를 변경하지 않는다.(inplace operations(A += 1)은 side-effet가 발생)
dataflow block은 side-effect free 함수만 허용함, side-effect가 있는 함수는 dataflow block에서 처리해야함
- (역자주) Relax는 모델의 순수 계산(graph) 과 운영/제어(control flow) 를 명확히 분리하려고 설계되었다. 그래서 R.dataflow() 내부는 최적화에 최적화된 구간, 외부는 학습/관리/제어 코드가 들어가는 구간으로 구분하는 것이 자연스러운 패턴
Dataflow Block을 자동으로 나누지 않고 수동으로 표시해야 하는 이유는
- auto inference 는 부정확 할수 있음 : packed function 호출(cuBLAS, cuDNN 등 외부 라이브러리 호출) 같은 경우 컴파일러 입장에서 확실하게 pure or not을 판단하기 어렵다.
- 많은 최적화는 Dataflow Block 안에서만 가능 : Fusion optimization 등은 Dataflow Block안에서만 가능(pure function 들만 모여 있기 때문에 연산 순서를 바꾸거나 합치는(fusion) 것이 안전합니다.)
- (역자 주) 컴파일러가 잘못 Dataflow Block 경계를 잡으면 최적화가 잘못되거나 성능에 영항을 줄 수 있다.)
Relax Creation
Relax functions을 정의하는 다양한 방법에 대해 다룬다.
Create Relax programs using TVMScript
TVMScript는 TVM IR을 표현하기 위한 domain-specific language이다.
- python 형태의 언어이며 TensorIR and Relax function 둘다 포함한다.
|
|
Relax는 graph-level IR 뿐만 아니라 cross-level representation과 transformation도 지원한다. 구체적으로 말하자면 Relax 함수에서 TensorIR 함수를 직접 호출할 수 있다.
|
|
show()로 출력을 확인해보면 작성한 TVMScript 코드와 출력이 다름을 볼수 있는데 이는 출력 시 syntax sugar 등이 표준 포맷으로 출력되기 때문이다. 예를 들어 작성 시 한라인에 여러 operation을 결합하여 작성할 수 있으나 출력시에는 한라인에 하나의 오퍼레이션이 결합되도록 출력된다.
|
|
Create Relax programs using NNModule API
TVM은 Relax 프로그래밍을 위한 PyTorch-like API인 Relax NNModule API 지원한다.
NNModule을 정의한 후 이를 export_tvm을 활용하여 TVM IRModule로 변환할 수 있다.
|
|
또한 NNModule에 customized function call을 삽입할 수 있다.
- Tensor Expression(TE), TensorIR functions, other TVM packed functions 등
|
|
Create Relax programs using Block Builder API
TVM은 Relax 프로그래밍을 위한 Block Builder API 를 제공한다. 이는 IR builder API로 좀 더 low-level이며 customized pass를 기술하기 위한 TVM 내부 로직에 널리 쓰인다.
|
|
Block Builder API는 유저 친화적이지 않지만 가장 낮은 수준의 API이며 IR definition과 밀접하게 작동한다. TVM은 ML 모델을 정의하거나 transform하고자 하는 사용자들은 TVMScript나 NNModule API를 사용하는 것을 추천한다. 그러나 복잡한 transformation을 원한다면 Block Builder API가 좀 더 유연한 선택이다.
Transformation
Transformation은 Hardware Backend와 최적화 및 통합하기 위한 컴파일 flow의 핵심 요소이다. 2항의 NNModule API 예제인 class NNModule(nn.Module)을 이용하여 예제를 진행한다.
Apply transformations
Pass는 Transformation을 Relax 프로그램에 적용하기 위한 주요 방법이다.
첫번째 단계로 built-in pass인 LegalizeOps를 적용하여 high-level operator들을 low-level operator로 lowering 할 수 있다.
(본문을 통해 pass가 적용된 결과를 확인하면 add, matmul등이 TensorIR로 변환되고 R.call_tir을 통해 호출되는 형태로 변환된 것을 확인할 수 있다.)
|
|
결과로 부터 high-level operator(aka relax.op)가 이에 대응되는 low-level operator(aka relax.call_tir)로 교체된 것을 볼 수 있다. fusion optimization(연산자 융합)은 Pass의 집합을 적용하여 수행할 수 있다.
|
|
본문의 결과로 부터 matmul, add, relu 연산자가 하나의 커널(aka call_tir)로 합쳐진 것을 볼 수 있다.
지원하는 Built-in pass들은 relax.transform을 참조하면 확인할 수 있다.
Custom Passes
Custom pass를 정의하는 방법을 확인하기 위해 relu를 gelu로 변환하는 예제를 수행해보자
- (역자주) gelu : transform 등 최신 모델의 활성함수로 GELU 함수는 표준 가우신안 누적 분포 함수 인 xΦ(x)로 정의
|
|
위의 mutator를 적용한 pass를 이용해 trasnformation
|
|
결과를 확인해보면 relax.nn.relu operator가 relax.nn.gelu 로 변경된 겻을 확인할 수 있다. 자세한 내용은 relax.expr_functor.PyExprMutator 참고