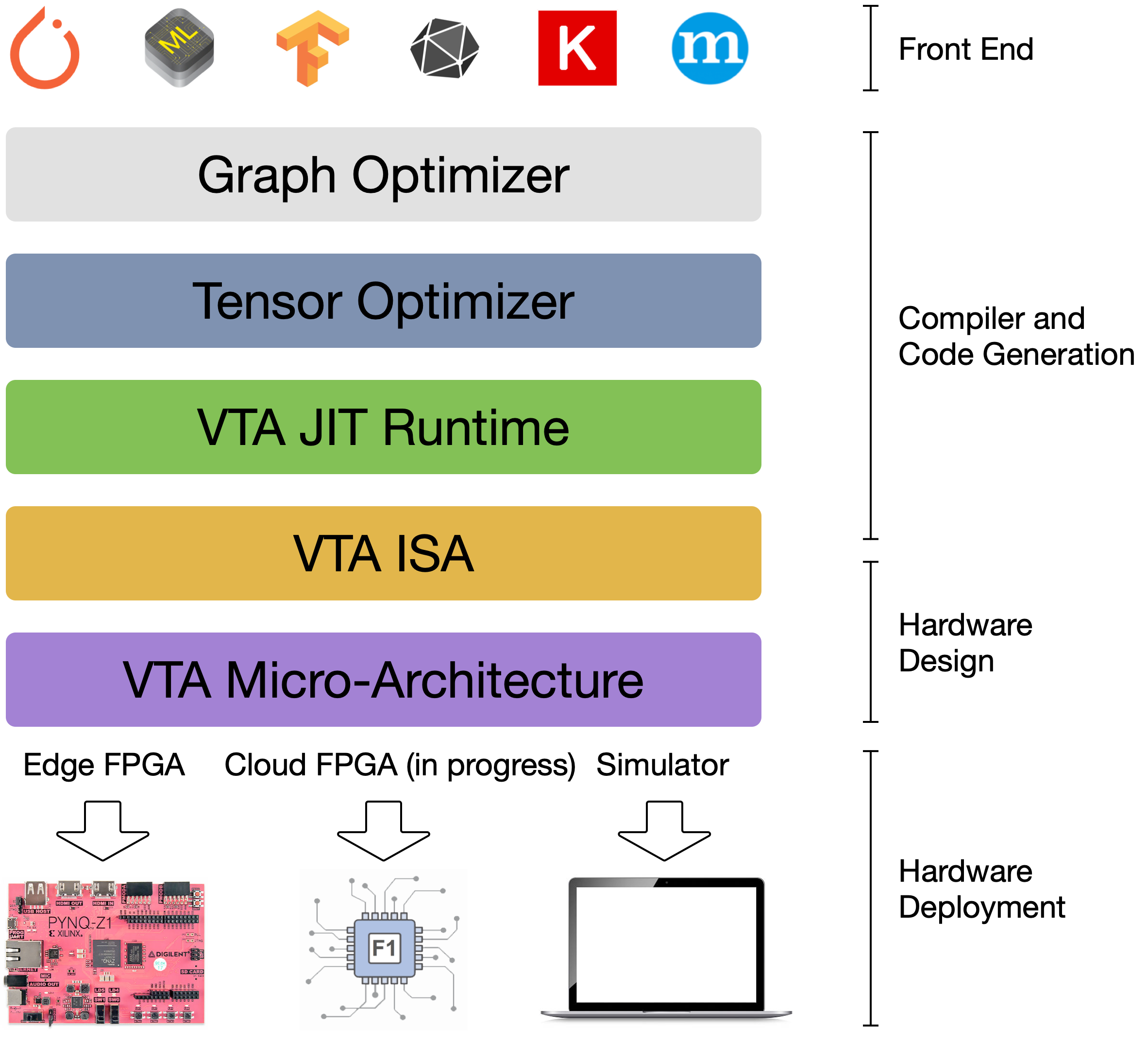
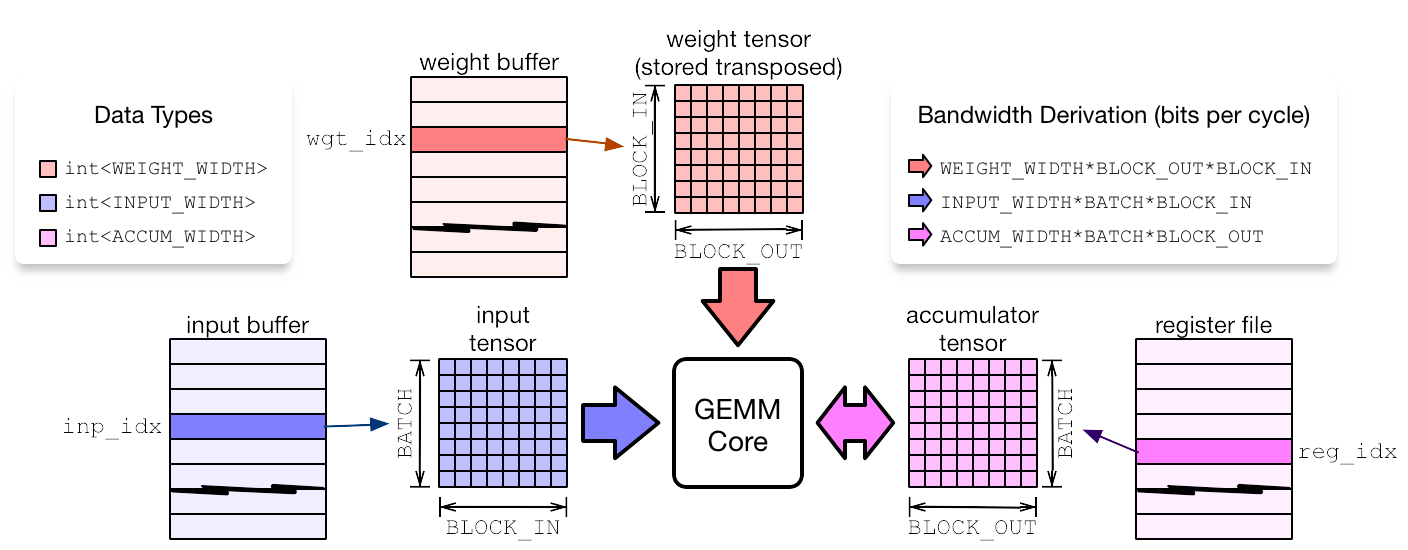
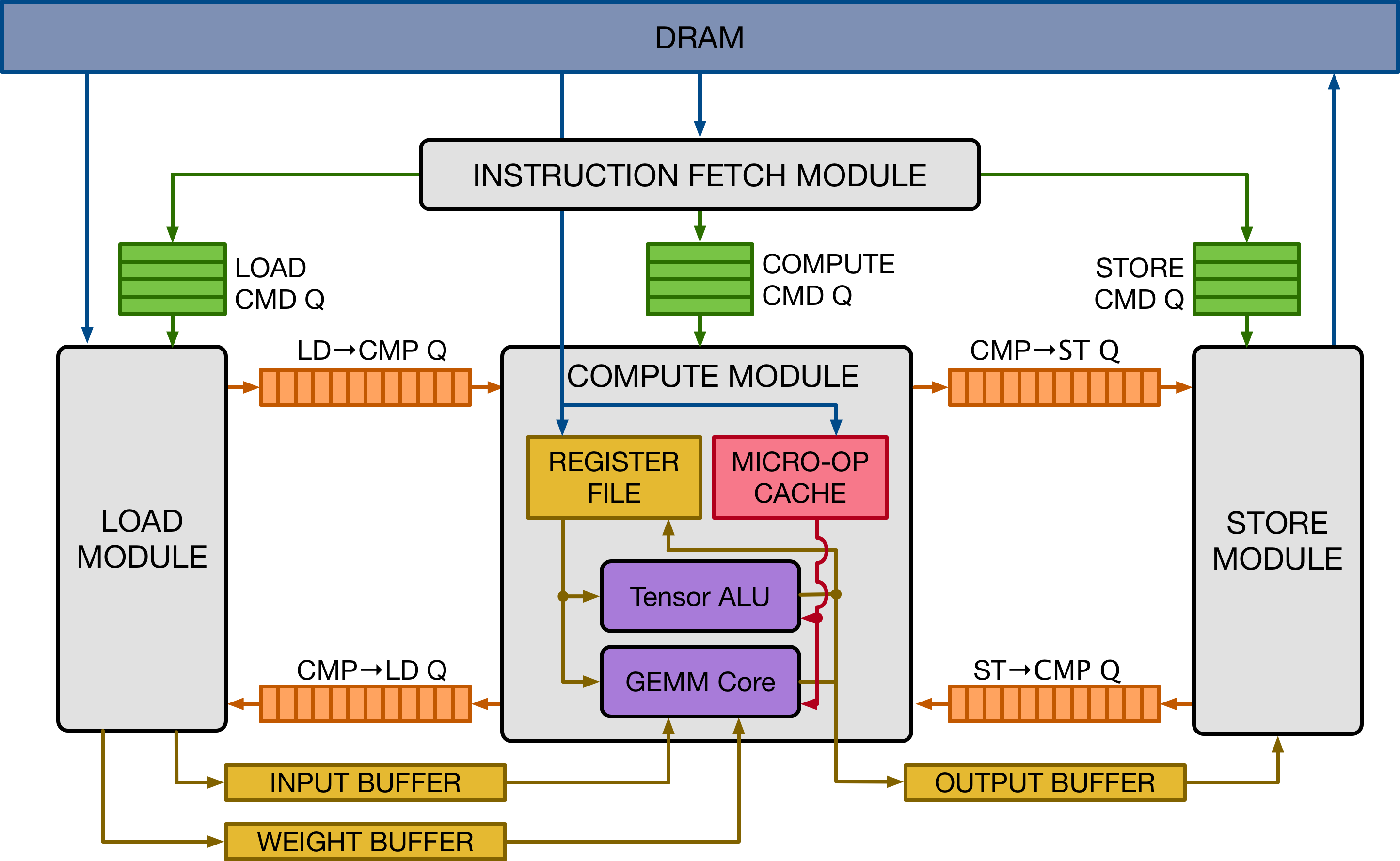
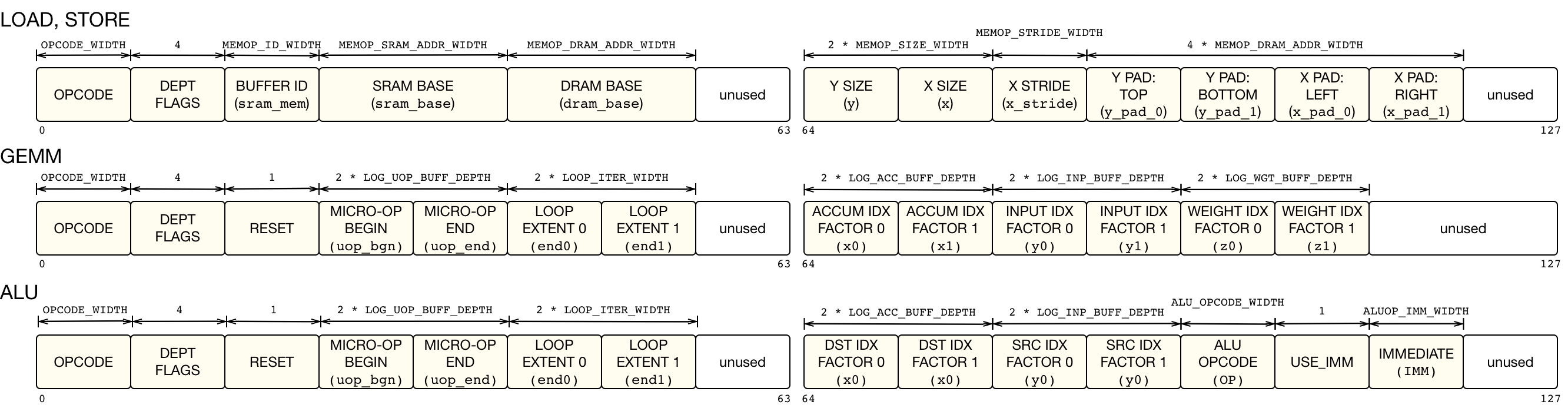
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
void gemm(
insn_T insn_raw,
uop_T uop_mem[VTA_UOP_BUFF_DEPTH],
bus_T acc_mem[VTA_ACC_BUFF_DEPTH][ACC_MAT_AXI_RATIO],
bus_T inp_mem[VTA_INP_BUFF_DEPTH][INP_MAT_AXI_RATIO],
bus_T wgt_mem[VTA_WGT_BUFF_DEPTH][WGT_MAT_AXI_RATIO],
bus_T out_mem[VTA_ACC_BUFF_DEPTH][OUT_MAT_AXI_RATIO]) {
#pragma HLS INLINE
VTAGemInsn insn = *((VTAGemInsn *) &insn_raw);
// Loop offset
acc_idx_T dst_offset_out = 0;
inp_idx_T src_offset_out = 0;
wgt_idx_T wgt_offset_out = 0;
// Outer Loop
EXE_OUT_LOOP: for (int it_out = 0; it_out < insn.iter_out; it_out++) {
acc_idx_T dst_offset_in = dst_offset_out;
inp_idx_T src_offset_in = src_offset_out;
wgt_idx_T wgt_offset_in = wgt_offset_out;
// Inner Loop
EXE_IN_LOOP: for (int it_in = 0; it_in < insn.iter_in; it_in++) {
// Iterate over micro op
READ_GEMM_UOP: for (int upc = insn.uop_bgn; upc < insn.uop_end; upc++) {
#pragma HLS PIPELINE II = 1
// Read micro-op fields
uop_T uop = uop_mem[upc];
// Decode indices
acc_idx_T dst_idx =
uop.range(VTA_UOP_GEM_0_1, VTA_UOP_GEM_0_0) + dst_offset_in;
inp_idx_T src_idx =
uop.range(VTA_UOP_GEM_1_1, VTA_UOP_GEM_1_0) + src_offset_in;
wgt_idx_T wgt_idx =
uop.range(VTA_UOP_GEM_2_1, VTA_UOP_GEM_2_0) + wgt_offset_in;
// Read in weight tensor
wgt_T w_tensor[VTA_BLOCK_OUT][VTA_BLOCK_IN];
read_tensor<bus_T, wgt_T, wgt_idx_T, VTA_BUS_WIDTH, VTA_WGT_WIDTH, VTA_BLOCK_OUT, VTA_BLOCK_IN>(wgt_idx, wgt_mem, w_tensor);
// Read in input tensor
inp_T i_tensor[VTA_BATCH][VTA_BLOCK_IN];
read_tensor<bus_T, inp_T, inp_idx_T, VTA_BUS_WIDTH, VTA_INP_WIDTH, VTA_BATCH, VTA_BLOCK_IN>(src_idx, inp_mem, i_tensor);
// Read in accum tensor
acc_T a_tensor[VTA_BATCH][VTA_BLOCK_OUT];
read_tensor<bus_T, acc_T, acc_idx_T, VTA_BUS_WIDTH, VTA_ACC_WIDTH, VTA_BATCH, VTA_BLOCK_OUT>(dst_idx, acc_mem, a_tensor);
// Output tensor
out_T o_tensor[VTA_BATCH][VTA_BLOCK_OUT];
// Inner GEMM loop
for (int b = 0; b < VTA_BATCH; b++) {
for (int oc = 0; oc < VTA_BLOCK_OUT; oc++) {
// Initialize the accumulator values
acc_T accum = a_tensor[b][oc];
// Dot product sum
sum_T tmp = 0;
// Inner matrix multiplication loop (input channel/feature)
for (int ic = 0; ic < VTA_BLOCK_IN; ic++) {
wgt_T w_elem = w_tensor[oc][ic];
inp_T i_elem = i_tensor[b][ic];
mul_T prod_dsp = i_elem * w_elem;
tmp += (sum_T) prod_dsp;
}
// Update summation
accum += (acc_T) tmp;
// Write back result acc_mem
a_tensor[b][oc] = insn.reset_reg ? (acc_T) 0 : accum;
// And output vector
o_tensor[b][oc] = (out_T) accum.range(VTA_OUT_WIDTH - 1, 0);
}
}
// Write the results back into accumulator
write_tensor<bus_T, acc_T, acc_idx_T, VTA_BUS_WIDTH, VTA_ACC_WIDTH, VTA_BATCH, VTA_BLOCK_OUT>(dst_idx, a_tensor, acc_mem);
// Write the results back in the output buffer
write_tensor<bus_T, out_T, acc_idx_T, VTA_BUS_WIDTH, VTA_OUT_WIDTH, VTA_BATCH, VTA_BLOCK_OUT>(dst_idx, o_tensor, out_mem);
}
// Update offsets
dst_offset_in += insn.dst_factor_in;
src_offset_in += insn.src_factor_in;
wgt_offset_in += insn.wgt_factor_in;
}
// Update offsets
dst_offset_out += insn.dst_factor_out;
src_offset_out += insn.src_factor_out;
wgt_offset_out += insn.wgt_factor_out;
}
}
|